什麼是 RAG?一篇文章看懂 Retrieval-Augmented Generation
ChatGPT 現在幾乎已經融入了大家的日常生活,不只是工程師會使用它,各行各業或是學生也會使用到,這類的 LLM 看似變成了人類的夥伴,幫助人類解惑及做事,但真的可以完全信任、相信它嗎?
我覺得不行,因為它有時候會唬爛。
AI 幻覺 (hallucination)
首先要提到這個,所謂幻覺,就是 LLM 在不知道答案的情況下,仍然會產生看起來像是真的錯誤答案,但其實是合理的,因為語言模型的本質是「預測最可能的文字組合」,而不是「查證正確性」。
如果是你知道的東西,就是發現它正在一本正經的胡說八道,這時候可能就笑笑而過當作一個有趣的事情。
可怕的是你正在學一個知識,使用 ChatGPT 來學習一個你完全不懂的領域時,這種唬爛就非常可怕了,很大的機率你會被有條有理的胡扯給唬得一愣一愣的,個人經驗,遇到一些嚴肅的知識性問題,我有被 ChatGPT 憑空捏造的事實騙過,甚至會發現還會杜撰不存在的文獻。
那相對應處理這種情況就需要引入今天的主題 RAG(Retrieval-Augmented Generation) 技術。
RAG 的核心概念
Retrieval-Augmented Generation,中文就是檢索-增強 生成。
顧名思義概念把「查」的部分增強後再生成,意思是讓 LLM 在回答問題前先去資料庫「查資料」,之後才再生成回應。
在問問題前先跟 ai 說,請你先去看看相關的資料,再來生成回答,很大程度上避免了它去回答不知道的問題。
我們也可以確保說給 ai 看的資料是即時的,讓他不要用過時的資訊來生成回應。
簡單可以理解成:
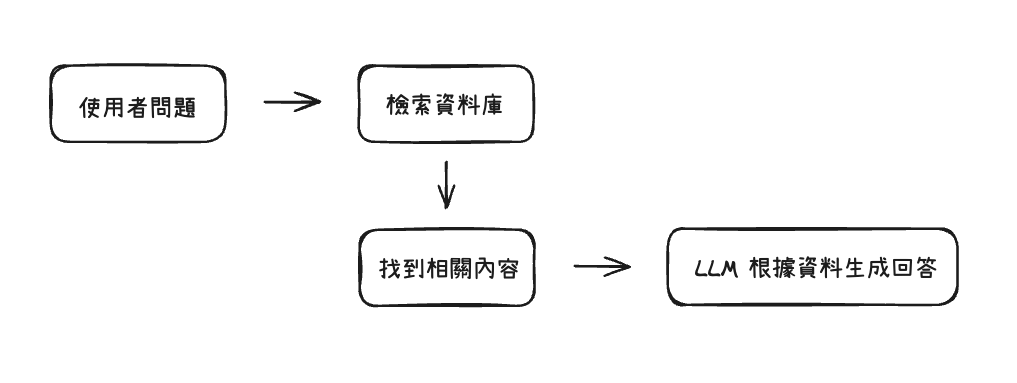
而詳細一點的話 RAG 這技術的流程可以拆成兩個階段:
- Retrieval (檢索)
使用者輸入一個問題後,RAG 系統會先把這個問題轉換成「向量」,之後才會去向量資料庫裡面去找出語意最相關的內容。
- Generation (生成)
接著,語言模型比如說 ChatGPT 會收到這些查找的內容,再根據這些內容來生成回應。
有一個小技巧是你可以在 prompt 裡強調說:「只根據提供的 context 回答,否則說不知道。」,這樣如果問題的答案不在檢索到的資料中,LLM 就能誠實回應「資料不足,無法回答」,降低了 AI 幻覺的風險,可喜可賀。
流程會變成這樣:
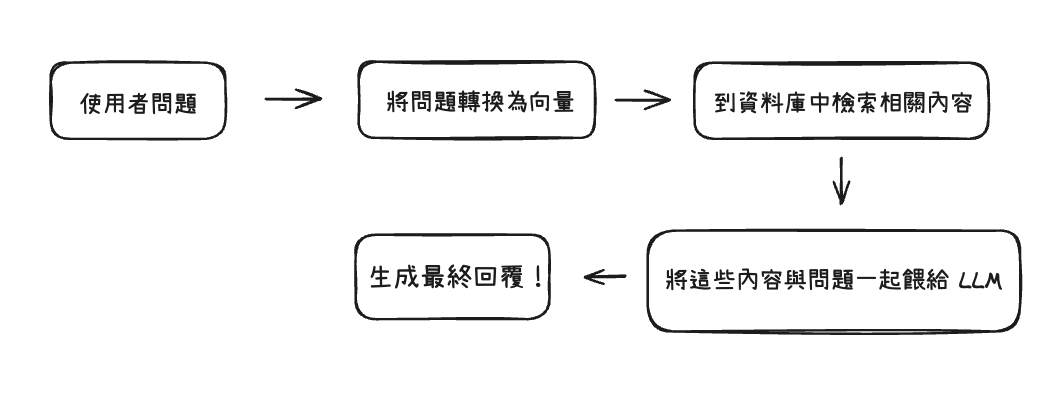
大致上概念是這樣,不過看完 Retrieval 的人可能會有一些疑惑
為什麼要把問題轉換成向量?
轉成向量後這些東西要放哪裡?
以下會來慢慢細說。
Embedding,把資料向量化吧!
關於為什麼要轉換呢?
首先思考一個問題,就是我們該怎麼讓機器知道說兩種資料像是兩段文字的意思很相近?
對人類來說,我們能理解漂亮和美麗、難過和悲傷、 請求和要求是相近的,因為我們能夠透過「語意相似度」來去判斷(現階段人類才有?)。
但對機器來說,「字面長得像」不代表「意思相近」。
上面提到 RAG 的檢索階段中,我們希望的目的是:
幫 LLM 從一堆資料中,找出跟使用者問題最有關的內容。
假如不轉換的話,使用傳統關鍵字搜尋,像 Google 那樣比對會如何?
就會變成看不懂同義詞也不能理解語意,你問「買手機」是找不到「購買 iPhone」的,或是你問「最近產品有什麼 Bug 嗎」也沒辦法找到需要修復的錯誤。
而向量搜尋是透過語意距離來比對的,不是靠字面相似度,所以更準確更接近語意。
在 RAG 中,文字就會透過 embedding 來轉換成向量!
這個時候就可以用數字的方式來表示「兩段文字意思有多接近」,用數學上的距離來衡量語意上的差異,也就是所謂的語意距離。
實務上會找一個語意模型,(像是 text-embedding-3-small 或 all-MiniLM)來把一段文字轉成數字組合的向量。
例如:
1 | "我想查詢今年 Q2 的報表" |
然後要比對的資料庫也會都轉成向量,再放進資料庫裡面,
這樣一來就可以利用數學的一些方法(可能像是餘弦相似度之類的,應該高中數學有教我覺得大概知道就好不用深究),快速計算出這個提問最接近哪些資料,再餵給 LLM 來生成回覆。
這邊簡簡單單的用 3 維向量來當範例,通常大概都會在 384 ~ 1536 維左右。
使用者輸入了這三段文字:
1 | "cat"(貓) |
經過了 embedding 模型處理過後:
1 | "cat" → [0.95, 0.10, 0.90] |
解釋一下這是我設計很簡化的3 維語意空間,每個詞語都被表示成一個 3 維向量,這三個維度是:
動物性
可食性
可愛度
邏輯大致上就是:
cat 貓貓
它非常像動物 → 0.95
幾乎不能吃? → 0.10
很可愛 → 0.90
apple 蘋果
完全不是動物 → 0.00
很好吃 → 0.95
應該也可愛? → 0.6
數學不好的朋友們可以先回憶起什麼是平面座標,有 x 軸跟 y 軸的那個,那就是平面向量也就是 2 維向量,之後就只是增加維度而已,還是一個地圖的概念。
向量在這邊就只是變成了「語意的座標」,每個維度都是語意的不同特徵,所謂的轉換也只是把文字給放進這個「語意地圖」裡面的某個點,點跟點之前的距離就是語意距離。
超級比一比:
cat 和 dog 的向量非常接近,那就代表他們在語意空間「語意相似」,所以向量距離小
cat 和 apple 向量距離很遠,因為它們語意差異大
這樣就能很直觀,如果維度多一點也能更準確地抓到語意相近的部分。這就是向量化資料技術存在的意義。
登登,所以現在電腦能夠透過數字化理解語意了,感謝飛天小 Embedding 的努力。

向量資料庫(Vector Database)
如果 embedding 是「把文字變成向量」,那還有個地方得放向量資料吧?
或是想試著用傳統資料庫來做到這件事情,那就值得來思考一下了。
傳統資料庫,像是 MySQL 或是 MongoDB 擅長的都是直接比對的查詢,比如找出所有「價格」的金額,但如果要問說找出「意思」或是「如何賺取更多錢」最接近的文件,那就不是比「字」了,而是要比「語意」,也就是上面提到比向量的距離。
而傳統資料庫做不太到這件事情,或是要做的非常的慢。
所以向量資料庫的作用這時候就登場了:
能夠儲存大量「文字對應的向量」
接收一個使用者問題 → 轉成向量 → 去資料庫找出「最接近」的資料
回傳前幾筆相似的內容(通常是 Top 3 或 Top 5)
概念大概是這樣,而現在市面上也有很多好用的向量資料庫了,比如 FAISS、Chroma、Weaviate、Pinecone,需要選型的時候可以再去超級比一比。
這邊重要的概念是向量資料庫被視為 RAG 架構中不可或缺的「資料搜尋引擎」,所以只要提到資料流動細節,往往脫離不了 embedding + 向量資料庫。
如果以上概念都 ok 沒問題的話,接下來要介紹的觀念也是屬於 RAG 中很重要的一環,那就是:
Chunk 拆分(Text Chunking)
- Chunk Overlap
簡單來說,就是不能把整坨資料塞進去做向量化,要先拆!
Embedding 存進向量資料庫之前
RAG 在檢索時會做 embedding 後再存到向量資料庫,這個概念沒問題,但是如果今天是很大的資料就會出事。
為什麼會出事,可以想像成如果你查詢的向量資料庫有一整份 PDF 好幾千個字,但是你問的問題只跟其他一段有關,這樣 LLM 處理起來會很費力。
一來要知道,目前來說 LLM 的上下文都是有限的,能使用的 token 不是想用就用,要考慮到為進去的資料不能超過限制。
二來拆成一小塊一小塊,對於提高 embedding 精準度是有幫助的,雖然太短也會缺乏語境,這塊會需要拿捏一個尺度,也就是 Chunk 的拆分策略是會影響效果,不是越長或是越短效果就越好。
一個精美 ai 產的示意圖,來表示從原始文件 → chunk 拆分 → embedding 的整個流程。
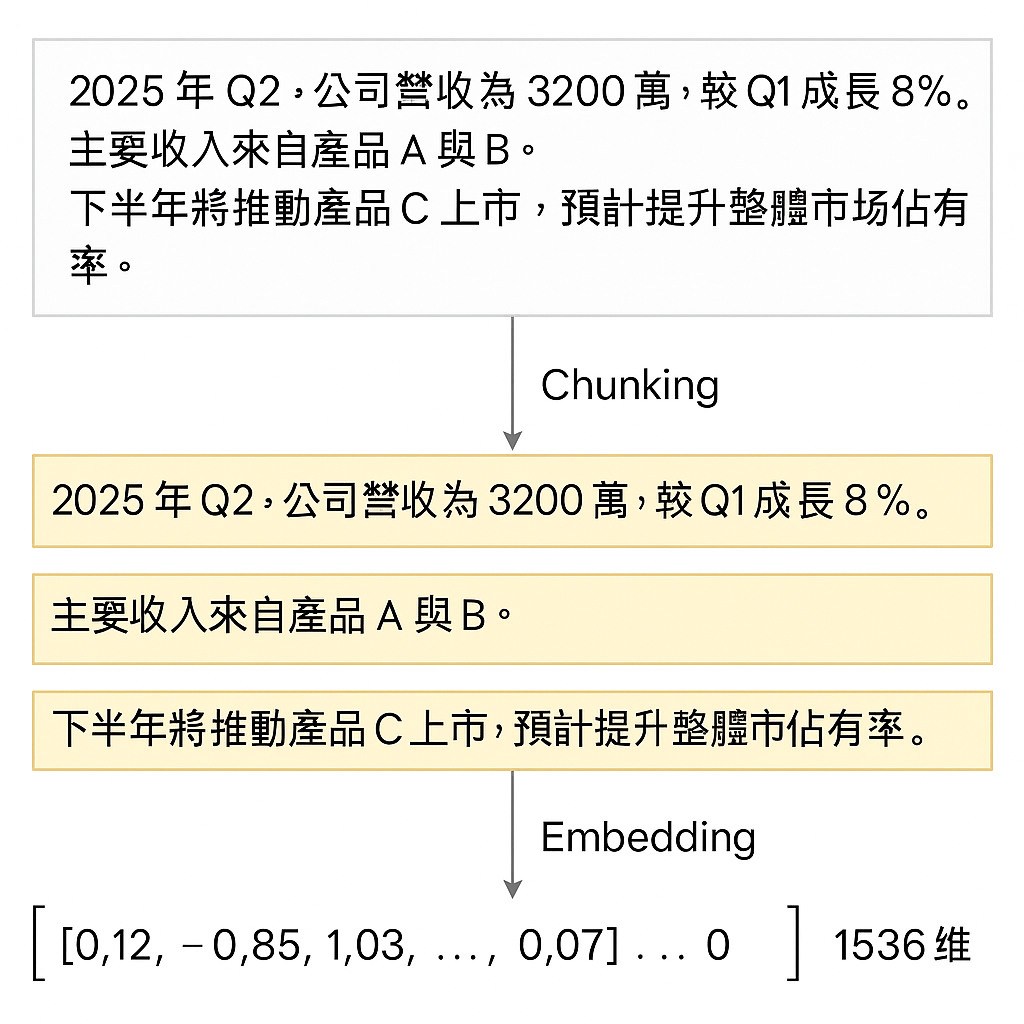
最簡單來說就是現階段把一大串內容直接丟給 AI 跑 Embedding 沒做 Chunk 它會爆炸。
跟前面簡單範例差別是切成一段一段後,每段做 embedding 時都存在一個向量,這樣使用者問問題時,就從這些「段落向量」中挑最相近的幾段。
常見的 Chunking 做法
用一個範例來說明,先設定原文是這樣:
1 | 我們在 Q1 推出了產品 A,Q2 營收因此成長 20%,下半年預計推出產品 B。 |
第一種,Fixed Length(固定長度切段)。
把每一段固定拆 N 個字或是 N 個 token,單純把每一句單程一段,會像是:
1 | Chunk 1:我們在 Q1 推出了產品 A, |
好實作也很簡單,但問題是有可能會漏掉某些語意,可以想像成如果有兩個 Chunk ,第一個 Chunk 是因為 XXX ,第二個 Chunk 是所以 OOO,但是光看第二個 Chunk 根本不會了解為什麼 OOO,語意遺失在第一個 Chunk 中了。
像是這個原文情境來說,如果我只讓 ai 檢索到 Chunk 2 的內容,就不會知道為什麼 「因此成長」的原因,模型可能看不到原因是產品 A 。
這個時候就會介紹到第二種方法 - Sliding Window(固定長度,有 overlap)
介紹前要先認識 Chunk Overlap 的概念。
簡單說就是讓部分內容重疊,意義上是避免我上述提到的問題,透過讓每個 Chunk 拆分時,和上一段有「部分內容重疊」,從而避免語意被切斷。
假設每段 overlap = 5 字,會像是:
1 | Chunk 1:我們在 Q1 推出了產品 A, |
這樣的好處是比起第一種,每段都含有點上一段的結尾,讓上下文變得更連貫些,即使只檢索到 Chunk 2,也能保有產品 A 的語境。
但缺點是會讓向量資料庫裡資料數變多(因為重複),增加儲存跟查詢成本,有好有壞看狀況。
結尾
知道以上關於 rag 的相關知識後,可能會想問那可以自己做一個 RAG 系統嗎? 還是只能等 OpenAI、Notion 這種大公司推出功能?
其實這兩種都可以。
現成的 RAG 工具已經蠻多了,可以直接拿來用,像是:
Notion AI
花費的部分也不需要太擔心,因為都有免費方案,想要嘗試使用了 RAG 技術的服務這些是好選擇。
另外,自己動手做也是完全可行的!
順便當作統整這篇所提到的概念,整理的流程會需要:
準備資料: 像是文字
切成段落:先進行 chunk 後進行 embedding,轉換成向量
放進去向量資料庫:像是 FAISS、Chroma
最後:使用者提問 → 轉成向量 → 想到相關內容 → 和問題一起丟給 LLM → 大功告成!
網路上有很多資源,如果沒頭緒可以關鍵字搜尋:自己動手做 RAG ,應該會有很多教學文章、影片、GitHub 範例可以參考,這邊就不細談囉。
最後,如果以一句話來說明 RAG 的價值,我認為它目的不是讓 AI 變得更聰明,而是變得更「可靠」,對於「AI 的回答能不能信任」,相信也是未來的核心議題之一。